
- Creatio 10x – co ogłoszono i co to zmienia dla polskich firm - 16 lipca 2026
- Jak CRM pomaga ograniczyć chaos rozproszonych narzędzi AI w firmie? - 2 lipca 2026
- Zbudowałeś narzędzia sprzedażowe z AI i masz chaos. Co teraz? - 23 czerwca 2026
19 lipca byłem akurat na wakacjach. Zdziwiły mnie wiadomości od znajomych, którzy pisali, że też trafili na nieplanowany urlop. Nie był to wcale odosobniony przypadek.
Feralnego piątku komputery odmówiły posłuszeństwa w bardzo wielu przedsiębiorstwach.
W Polsce problemy zgłaszał np. terminal kontenerowy w Gdańsku. Na świecie awaria dotknęła m.in.:
Zastanówmy się, czy całej sprawy można było uniknąć oraz co zrobić, by zabezpieczyć swój biznes przed podobnymi sytuacjami w przyszłości.
„Globalna awaria Microsoft” – o co chodziło?
Chociaż problem objawiał się brakiem dostępu do urządzeń z systemem operacyjnym Windows, nie był on spowodowany bezpośrednio przez Microsoft.
Sytuacja okazała się o wiele bardziej złożona.
Po czasie ustalono, że za awarię odpowiada producent nowej generacji antywirusa: firma CrowdStrike. Osoby, które skorzystały z dosłanej przez nich aktualizacji wprowadziły do swojego systemu wadliwy sterownik EDR Falcon Sensor.
Niedziałająca poprawka spowodowała wpadanie komputerów w tzw. “pętlę śmierci”. Polegało to na nieskutecznym restarcie urządzenia i wyświetleniu charakterystycznego niebieskiego powiadomienia z błędem.
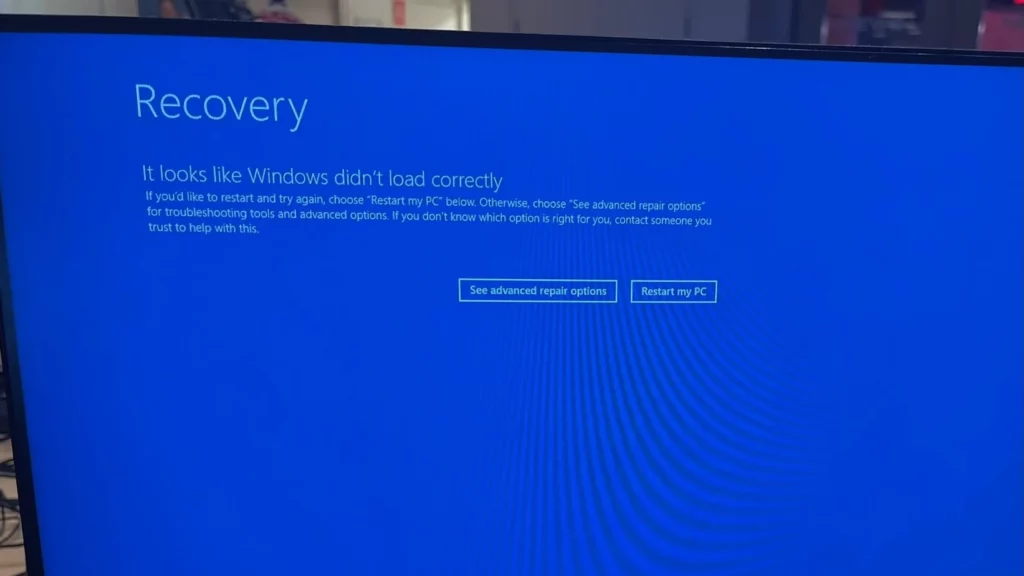
Wbrew początkowym obawom nie był to zatem atak hakerski, ale jak przyznał George Kurtz, CEO CrowdStrike: „incydent związany z bezpieczeństwem”.
O sprawie w następujących słowach napisał popularny portal Niebezpiecznik:
Windows nie mógł się uruchomić, bo ze względu na specyfikę oprogramowania CrowdStrike (i w zasadzie każdego EDR-a/antywirusa), zawierający błąd sterownik Falcon Sensora był ładowany na samym początku procesu bootowania systemu Windows, jako tzw. Early Launch Antimalware (ELAM) driver.
Dlaczego awaria dosięgła tylko (niektóre) firmy?
„Awaria Microsoft” dosięgła tylko firmy, ponieważ cały proces dotyczył aktualizacji wykorzystywanego korporacyjnie antywirusa.
Skali problemu nie pomogły realia popularnej współcześnie pracy zdalnej.
Po instalacji wadliwego sterownika przez Internet, ze wspomnianej „pętli śmierci”, komputery można było wyrwać tylko poprzez osobistą interwencję specjalisty IT. Naprawa wymagała bowiem uruchomienia systemu Windows w trybie safe mode.
Pracownicy znajdujący się poza siedzibami swoich firm mieli kłopot, by samodzielnie przeprowadzić niezbędne czynności naprawcze. Nie tylko dlatego, że nie posiedli specjalistycznych umiejętności, ale przede wszystkim dlatego, że (ze słusznych zresztą powodów) nie mają dostępu do ustawień administracyjnych.
Z braku działającego komputera (podstawowego narzędzia pracy) utrudnione było nawet samo zgłoszenie sprawy zespołowi helpdesk.
Prawdziwa przyczyna „awarii Microsoft”
Prawdziwa przyczyna awarii to jednak nie kwestia pracy zdalnej.
Nieobecność w biurze mogła co prawda wydłużyć proces naprawczy, ale sam problem wynikał ze sposobu dostarczenia nowej wersji antywirusa.
Ponieważ oprogramowanie od CrowdStrike jest aktualizowane wraz z Windowsem, nowe funkcje, fixy i tzw. łatki bezpieczeństwa trafiają do niego na skutek aktualizacji przez Internet.
Kiedy dostarczona przez producenta paczka okazała się wadliwa, problem rozprzestrzenił się u tych klientów, którzy w nieodpowiednim momencie pokusili się o aktualizację Windowsa. Albo u tych, u których aktualizacja wywołała się automatycznie.
Nie miało to zatem bezpośredniego związku z wewnętrznymi procesami w firmach dotkniętych awarią.
Winą można co najwyżej obarczać autorów wadliwego sterownika i zespół odpowiedzialny za przygotowanie aktualizacji do wdrożenia.

Przy okazji zastanawiający jest sam proces rozprzestrzeniania poprawek dla systemów, szczególnie takich hostowanych w chmurze.
Z jednej strony dużo mówi się o konieczności częstej aktualizacji cloudowych narzędzi. W ten sposób trafiają do nich nowe funkcje i konieczne fixy — nomen omen zabezpieczające przed problemami z użytkowaniem.
Z drugiej: pochopne lub po prostu samoczynne (bezobsługowe) wprowadzenie zmian do oprogramowania, może przynosić podobne lub jeszcze poważniejsze skutki niż sytuacja z 19 lipca.
Jak zagwarantować bezpieczeństwo firmowych systemów?
Decydując się na system, z którego będziecie korzystać w Waszej firmie, należy rozważyć wiele czynników. Sprawa bardzo często rozbija się o budżet i oferowane funkcje.
Sytuacja z 19 lipca pokazuje, jak bardzo istotny jest także element szeroko rozumianego bezpieczeństwa danych i infrastruktury.

Bezpieczeństwo infrastruktury eVolpe
Na dzień dzisiejszy nie znalazłem źródła, które na liczbach pokazywałoby, jak kosztowny dla wymienionych we wstępie podmiotów, okazał się wywołany awarią przestój. Śmiem jednak sądzić, że bardzo.
Wyłączenie terminala lotów czy oddziału banku na cały dzień i bez wcześniejszego przygotowania — musiało się odbić na przychodach.
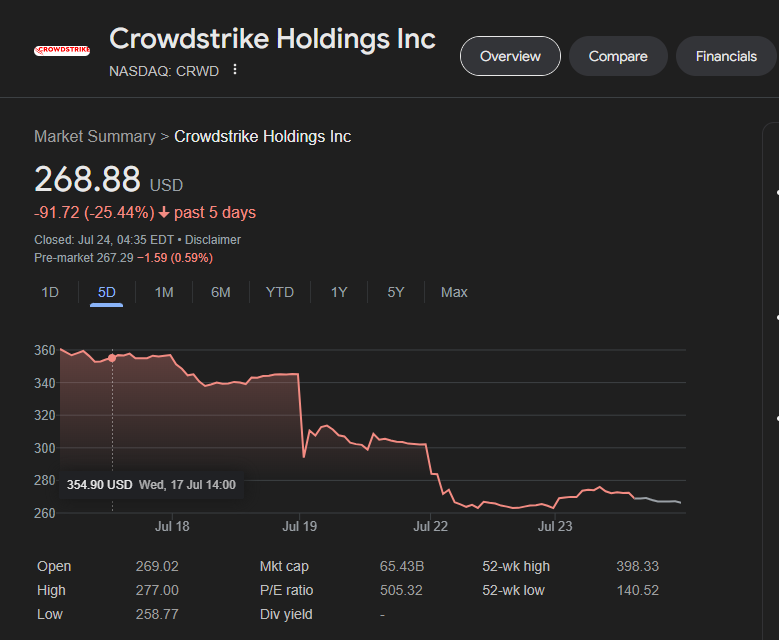
Zdarzenie z całą pewnością wpłynęło też na winowajców tego zamieszania. Na screenie poniżej wyraźnie widać moment, w którym giełda zareagowała na medialne doniesienia o problemie z oprogramowaniem CrowdStrike.
Firmowy system odporny na awarie
W jaki sposób można się uchronić przed wgraniem niechcianego sterownika?
Wiele polskich firm stawia na oprogramowanie Open Source hostowane On-Premises.
Oznacza to, że żadna poprawka nie trafia do ich systemu w nieoczekiwany sposób. Upgrade aplikacji przygotowywany jest indywidualnie, z uwzględnieniem uruchomionych integracji czy wprowadzonych wcześniej zmian funkcjonalnych.
Nie trzeba się też natychmiastowo „podnosić” do najnowszej dostępnej wersji.
W przypadku Open Source On-Premises możesz wskazać stabilną, sprawdzoną aktualizację, co do której nie ma najmniejszych wątpliwości, że nie wywołuje niespodziewanego błędu.
Aktualizacja systemu zgodnie z metodyką Agile
Najlepiej kiedy zarówno wdrożenie jak i obsługa serwisowa czy upgrade’y oprogramowania realizowane są zgodnie z metodyką Agile i frameworkiem Scrum.
W przytoczonym dzisiaj kontekście, pośród wielu zalet takiego podejścia, wyróżnia się aktywne zaangażowanie przedstawiciela klienta w projekt.
W praktyce – Produkt Owner, czyli koordynator wskazany spośród osób zatrudnionych w Waszej firmie – zamawia, testuje i akceptuje wszelkie zmiany. W imieniu organizacji komunikuje się z zespołem deweloperskim i administracyjnym oraz dba, by cały proces przebiegał zgodnie z życzeniem inwestora.
Taki podział ról jest nie tylko efektywny, opłacalny (realizowane są tylko takie prace, które są rzeczywiście potrzebne), ale przede wszystkim: gwarantuje bezpieczeństwo i ciągłość działania firmowego systemu.
TL;DR?
W przeciwieństwie do tego, co swoim klientom zafundował niedawno CrowdStrike, rozwiązanie Open Source On-Premises, niczym Cię nie zaskoczy. A już na pewno nie niespodziewaną, niezamówioną aktualizacją, która zamiast realnej funkcjonalności wprowadza zamęt i zatrzymuje Twój biznes na wiele godzin.
To Ty wskazujesz dzień i godzinę, kiedy cokolwiek trafia na produkcję. Masz też czas zakomunikować całą sprawę swoim klientom oraz pracownikom. A co chyba najistotniejsze: wszelkie zmiany weryfikujesz wcześniej w lustrzanym środowisku testowym.
Jesteś gotowy na prowadzenie dużego projektu wdrożeniowego w Twojej firmie?
Wiesz, o co zapytać dostawcę? Jak przygotować własny zespół? Jak stworzyć skuteczne zapytanie ofertowe? Jaką metodykę wybrać? Na co zwrócić uwagę negocjując umowę wdrożeniową i serwisową?
Specjalnie dla Ciebie stworzyliśmy darmowy kurs mailowy przygotowujący do prowadzenia wdrożeń.
Codziennie przez dwa tygodnie otrzymasz od nas na swoją skrzynkę kolejną dawkę wiedzy, która pozwoli odnaleźć Ci się w tym skomplikowanym procesie.
Darmowy kurs mailowy
- Creatio 10x – co ogłoszono i co to zmienia dla polskich firm - 16 lipca 2026
- Jak CRM pomaga ograniczyć chaos rozproszonych narzędzi AI w firmie? - 2 lipca 2026
- Zbudowałeś narzędzia sprzedażowe z AI i masz chaos. Co teraz? - 23 czerwca 2026


